








http://blog.kaggle.com/2017/05/16/data-science-bowl-2017-predicting-lung-cancer-solution-write-up-team-deep-breath/
(구글 번역 & 일부 편집)
Data Science Bowl은 Kaggle이 주최하는 연례 데이터 과학 경시 대회입니다. 에서 올해 목표는 년 이내에 암 진단을 사람들의 가슴 CT 스캔을 기반으로 폐암을 발견하는 것이었다.
이러한 어려움을 해결하기 위해 우리는 의료 영상 분석이나 암 예측에 대한 구체적인 지식이없는 기계 학습에 능통 한 사람들로 구성된 팀을 구성했습니다. 따라서 경쟁은 우리에게 고귀한 도전이자 훌륭한 학습 경험이었습니다.
대회가 끝나고 우리 팀 Deep Breath 가 9 위를 차지했습니다! 이 게시물에서 우리는 우리의 접근 방식을 설명합니다.
Deep Breath 팀은 Andreas Verleysen , Elias Vansteenkiste , Fréderic Godin , Ira Korshunova , Jonas Degrave , Lionel Pigou 및 Matthias Freiberger로 구성 됩니다. 우리는 모두 겐트 대학의 박사 과정 학생 및 박사후 과정입니다.
소개
폐암은 전 세계적으로 암 사망의 가장 흔한 원인입니다. 유방암에 이어 두 번째로 유방암은 가장 흔한 형태의 암이기도합니다. 폐암 사망을 예방하기 위해 조기 발견 이 폐암 환자의 생존율을 두 배로 하기 때문에 고위험군의 개인은 저선량 CT 스캔으로 선별 검사를 받는다 . CT 스캔에서 암 병변을 자동으로 식별하면 방사선 전문의가 많은 시간을 절약 할 수 있습니다. 그것은 더 합당한 진단을 할 것이고, 따라서 더 많은 생명을 구할 것입니다.
흉부의 CT 스캔에서 시작하여 폐암을 예측하기 위해 전체적인 전략은 고 차원 CT 스캔을 관심 대상의 일부 영역으로 축소하는 것이 었습니다. 이 관심 영역에서 시작하여 폐암을 예측하려고했습니다. 다음에서는 관심 영역을 추출하고 관심 영역에서부터 최종 예측을 수행하기 위해 여러 네트워크를 어떻게 훈련했는지 설명합니다.
이 게시물은 꽤 길기 때문에 다음 섹션을 건너 뛸 수있는 클릭 할 수있는 개요가 있습니다.
건초 더미의 바늘
누군가가 폐암에 걸릴지를 결정하기 위해 우리는 악성 폐결절의 초기 단계를 찾아야합니다. 폐 CT 스캔에서 조기 발견 악성 결절은 건초 더미에서 바늘을 찾는 것과 같습니다. 이 문장을 뒷받침하기 위해 LUng Node Analysis Grand Challenge 의 LIDC / IDRI 데이터 세트에있는 악성 결절의 예를 살펴 보겠습니다 . 방사선 학자의 상세한 주석이 포함되어 있으므로이 데이터 세트를 우리의 접근 방식에 광범위하게 사용했습니다.
공식 이름의 어리 석음을 감안할 때, 일반적으로 LUNA 데이터 세트 라고하며, 다음에서이 이름 을 사용합니다.


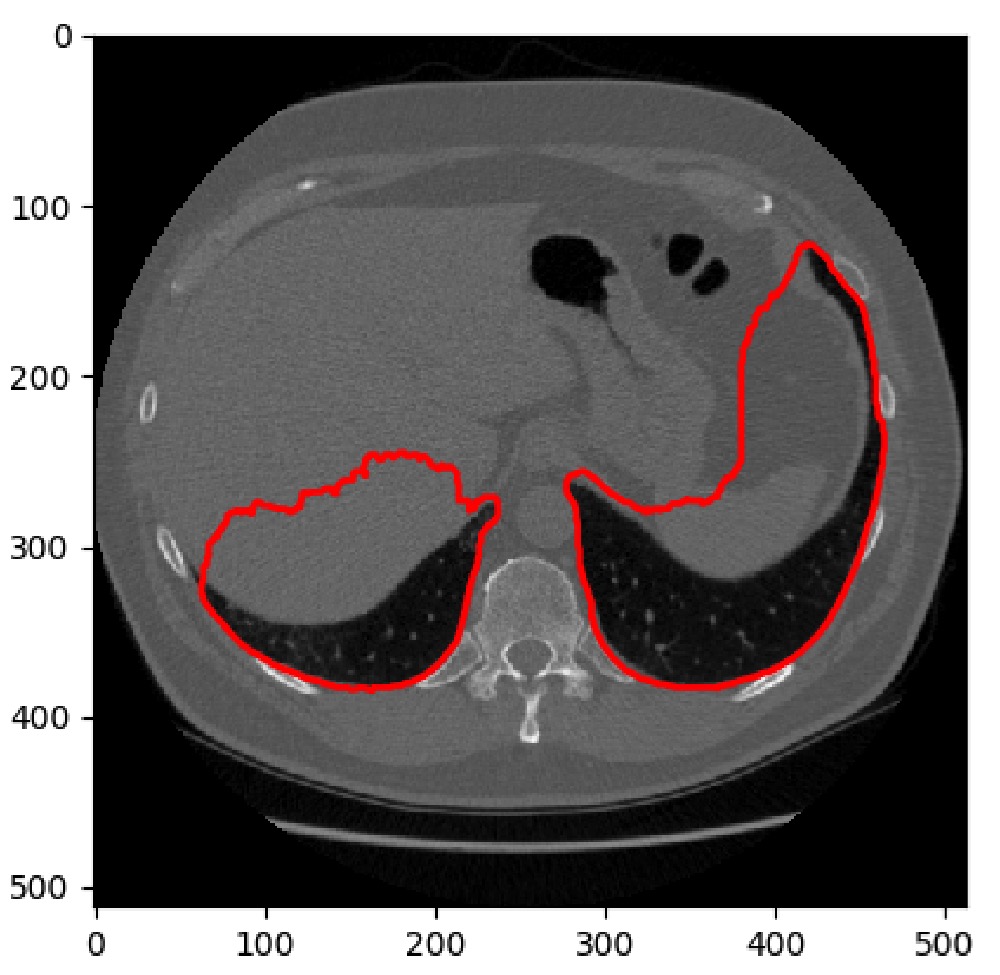
LUNA 데이터 세트의 평균 악성 결절의 반경은 4.8mm이고 일반적인 CT 스캔은 400mm x 400mm x 400mm의 부피를 포착합니다. 따라서 우리는 입력 볼륨보다 거의 백만 배 작은 기능을 찾고 있습니다. 또한이 기능은 전체 입력 음량의 분류를 결정합니다. 이는 CT 스캔을 방사선 전문의에게 막대한 부담으로 만들고 컨볼 루션 네트워크를 사용하는 기존의 분류 알고리즘에 대한 어려운 작업을 만듭니다.
이 문제는 스캔 한 날짜로부터 1 년 이내에 폐암으로 진단 될 환자의 CT 스캔에서 시작하여 폐암을 예측해야하기 때문에 우리의 경우에는 더욱 심각합니다. LUNA 데이터 세트에는 이미 폐암으로 진단 된 환자가 포함되어 있습니다. 우리의 경우 환자들은 아직 악성 결절을 가지지 못했을 수 있습니다. 따라서 경쟁에서 나온 데이터와 라벨을 직접 훈련하는 것은 효과가 없을 것이라고 생각하는 것이 합리적입니다. 그러나 우리는 어쨌든 시도해보고 네트워크가 교육 데이터의 편차 이상을 배우지 못한다는 사실을 관찰했습니다.
결절 탐지
결절 세분화
검사에서 정보의 양을 줄이기 위해, 우리는 먼저 폐 결절을 탐지하려고했습니다.
우리는 입력 스캔에서 결절을 분할하기위한 네트워크를 구축했습니다. LUNA 데이터 세트는 환자의 각 결절에 대한 주석을 포함합니다. 이러한 주석에는 결절의 위치와 직경이 포함됩니다. 이 정보를 사용하여 세분화 네트워크를 교육했습니다.
흉부 스캔은 다양한 CT 스캐너에 의해 생성되며, 이로 인해 원래 스캔의 복셀 사이의 간격이 달라집니다. 우리는 모든 CT 스캔을 재조정하고 보간하여 각 복셀이 1x1x1 mm 큐브를 나타낼 수 있도록했습니다. 세그먼테이션 네트워크를 교육하기 위해 64x64x64 패치를 CT 스캔에서 잘라내어 세그먼테이션 네트워크의 입력에 공급합니다. 각 패치에 대해 지상 진실은 32x32x32 mm 바이너리 마스크입니다. 바이너리 마스크의 각 복셀은 복셀이 결절 안에 있는지 여부를 나타냅니다. 마스크는 결절 주석의 직경을 사용하여 구성됩니다.
intersection = sum(y_true * y_pred)
dice = (2. * intersection) / (sum(y_true) + sum(y_pred))객관적인 함수로서 우리는 Dice 계수를 최적화하도록 선택합니다. 주사위 계수는 이미지 세분화에 일반적으로 사용되는 통계입니다. 조기 암 검진에 중요한 작은 결절에 대한 교육을 할 때 발생하는 불균형에 대해 잘 작동합니다. 작은 결절은 결절의 내부와 외부의 복셀 수 사이의 지상 진실 마스크에 높은 불균형을 가지고 있습니다.
주사위 계수를 사용하는 단점은 지상 진실 마스크 안에 결절이 없으면 기본값이 0입니다. 우리가 네트워크에 공급하는 각 패치에는 결절이 있어야합니다. 추가 변형을 도입하기 위해 번역 및 회전 보강을 적용합니다. 변환 및 회전 매개 변수는 결절의 일부가 64x64x64 입력 패치의 중심을 중심으로 32x32x32 큐브 안에 유지되도록 선택됩니다.
네트워크 구조는 다음 회로도에 나와 있습니다. 이 아키텍처는 주로 2D 이미지 세분화를위한 공통 아키텍처 인 U-net 아키텍처를 기반으로합니다 . 우리는 개념을 채택하고 3D 입력 텐서에 적용했습니다. 우리의 아키텍처는 주로 패딩없이 3x3x3 필터 커널을 가진 컨볼 루션 레이어로 구성됩니다. 우리의 아키텍처는 하나의 최대 풀링 레이어만을 가지고 있습니다. 더 많은 풀링 레이어를 시도했지만 U-net 아키텍처보다 해상도가 더 낮을 수도 있습니다. Google의 세분화 네트워크의 입력 모양은 64x64x64입니다. U-net 아키텍처의 경우 입력 텐서는 572×572 모양입니다.
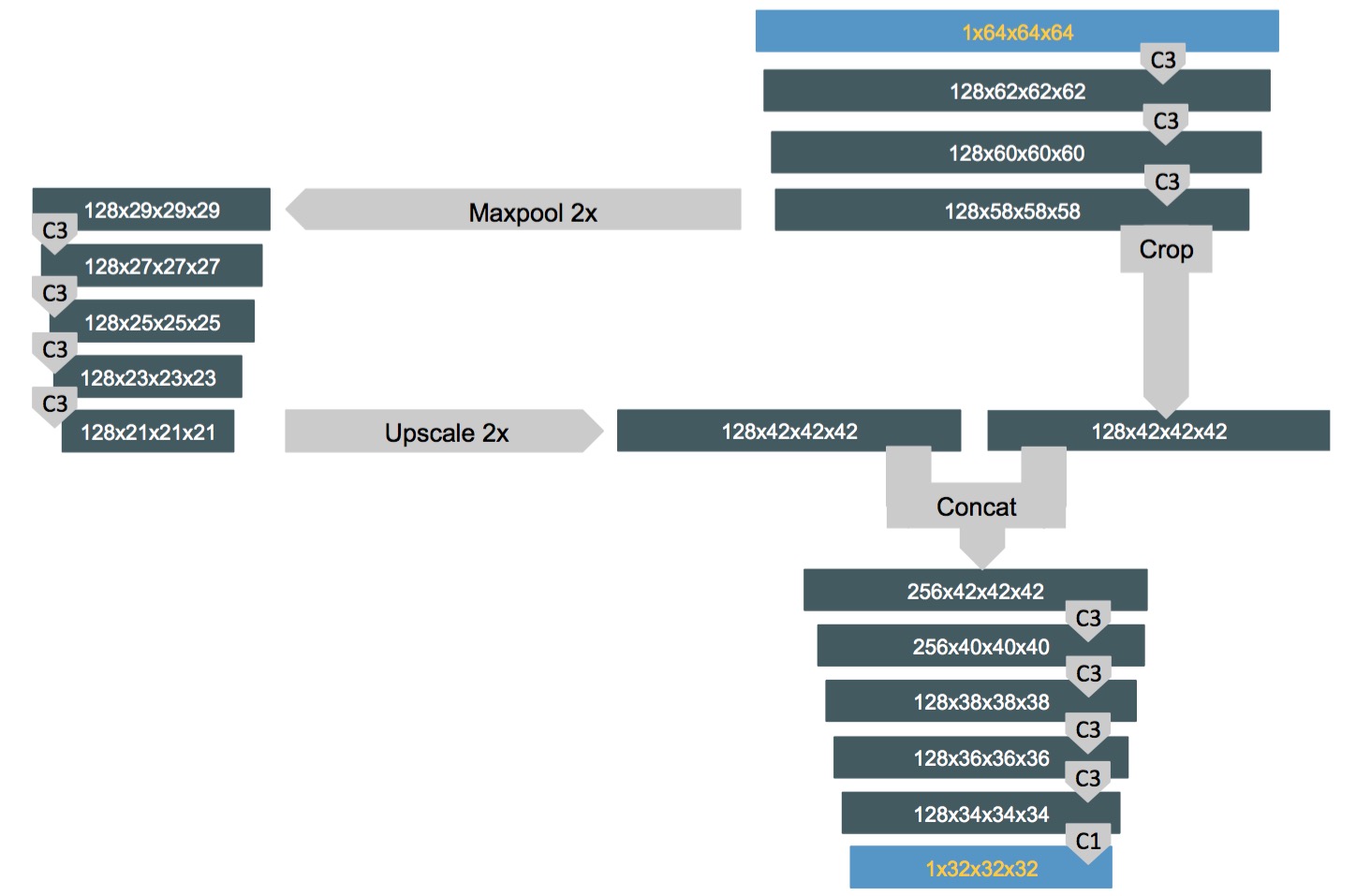
훈련 된 네트워크는 LUNA 및 DSB 데이터 세트에서 환자의 모든 CT 스캔을 분류하는 데 사용됩니다. 64x64x64 패치는 32x32x32의 보폭으로 볼륨에서 추출되고 예측 맵은 함께 스티칭됩니다. 결과 텐서에서 각 값은 복셀이 결절 내부에 위치 할 확률을 나타냅니다.
얼룩 감지
이 단계에서 우리는 폐 스캔 내 각 복셀에 대한 예측을 갖지만 결절의 중심을 찾고 싶습니다. 결절 센터는 확률이 높은 복셀의 얼룩을 찾는 것으로 발견됩니다. 얼룩이 발견되면 센터는 결절 후보의 중심으로 사용됩니다.
우리의 접근법에서 얼룩은 Laplacian 연산자의 덜 계산 집약적 인 근사를 사용하는 Gaussian (DoG) 방법 을 사용하여 감지됩니다.
우리는 skimage 패키지에서 사용할 수있는 구현을 사용했습니다.
방울이 검출 된 후, 우리는 중심선을 가진 결절 후보자의 목록으로 끝납니다.
불행히도이 목록에는 많은 결절 후보가 포함되어 있습니다. DSB 기차 데이터 세트의 CT 스캔의 경우, 평균 후보자 수는 153입니다.
두 필터 방법으로 후보자 수를 줄였습니다.
- 얼룩 검출 전에 폐 분할을 적용
- 위양성 감소 전문가 네트워크 교육
폐 분할
결절 분할 네트워크가 전 지구 적 맥락을 볼 수 없기 때문에 폐 외부에서 많은 오 탐지 (false positives)를 만들어 내었습니다. 이 문제를 완화하기 위해 우리는 손으로 설계 한 폐 분할 방법을 사용했습니다.
처음에는 Kaggle 자습서에서 제안 된 것과 유사한 전략을 사용했습니다. 폐를 분열시키기 위해 여러 형태의 수술법을 사용합니다. 육안 검사 후, 우리는 폐 분할의 품질 및 계산 시간이 구조 요소의 크기에 너무 의존한다는 것을 알아 냈습니다. 우리가 만든 두 번째 관찰은 2D 분할이 폐의 일반적인 조각에서만 잘 작동한다는 것입니다. 3 개 이상의 충치가있을 때마다 그 충치가 폐의 일부인지는 명확하지 않습니다.
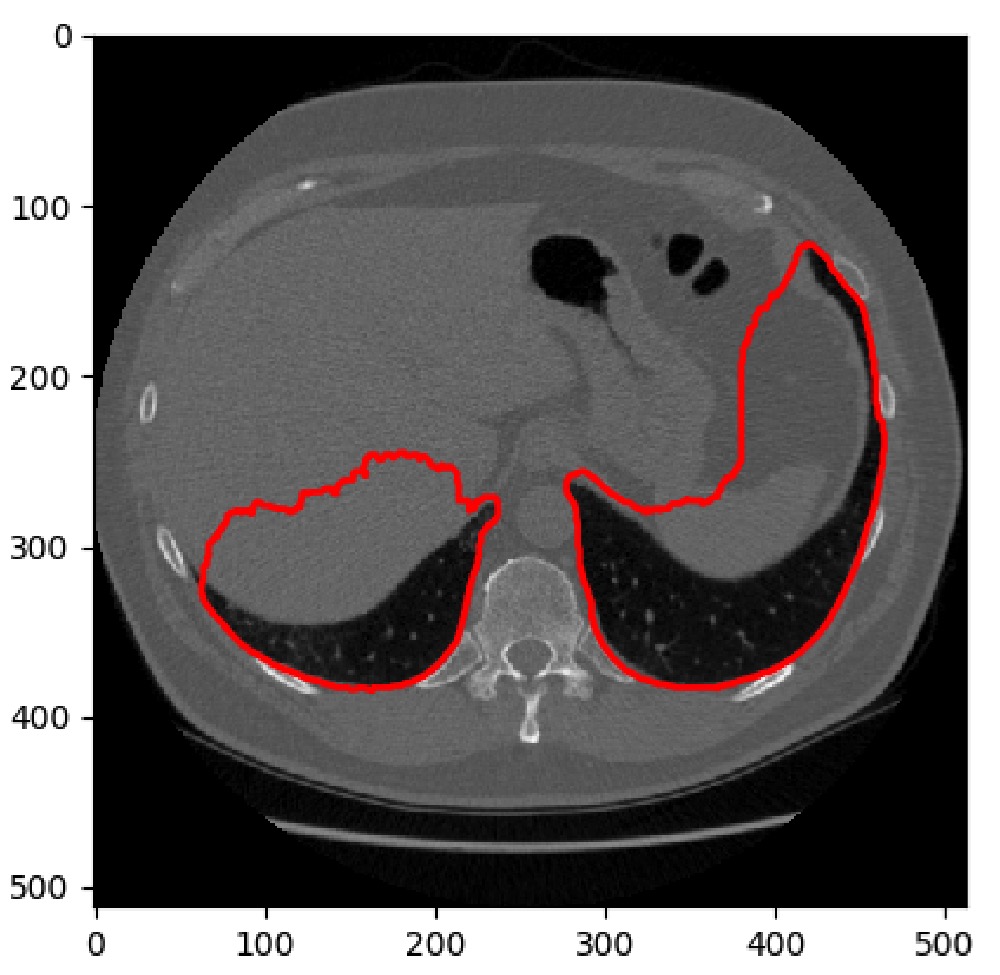
우리의 최종 접근 방식은 폐 주위에 설치된 볼록 선체에서 비 폐공을 잘라내는 데 초점을 둔 3D 접근법이었습니다.

위양성 감소
결절 후보자의 수를 줄이기 위해 우리는 전문가 네트워크를 훈련시켜 피 검체 검출 후 주어진 후보가 실제로 결절인지를 예측했습니다. 우리는 전문가의 네트워크를 훈련하기 위해 거짓 및 결절의 후보자 목록을 사용했습니다. LUNA 그랜드 챌린지에는 각 환자에 대한 거짓 및 실제 결절 후보자 목록을 제공하는 위양성 감축 경로가 있습니다.
우리의 위양성 감소 전문가를 교육하기 위해 48x48x48 패치를 사용하고 전체 회전 확대 및 약간의 병진 확대 (± 3mm)를 적용했습니다.
건축물
네트워크가 작은 결절 (지름이 3mm 미만)과 큰 결절 (직경> 30mm)을 모두 감지하기를 원할 경우 네트워크는 매우 좁고 넓은 수용 영역을 가진 두 가지 피처를 모두 교육 할 수 있어야합니다. 처음-resnet v2의 아키텍처는 아주 잘 다른 수용 필드와 교육 기능에 적합합니다. 우리의 아키텍처는 주로이 아키텍처를 기반으로합니다. 우리는 resnet v2의 시작을 단순화하고 그 원리를 3 차원 공간의 텐서에 적용했습니다. 재사용 가능한 유연 모듈을 증류했습니다.
이 기본 블록은 네트워크의 공간 치수의 수, 매개 변수 및 크기를 실험하는 데 사용되었습니다.
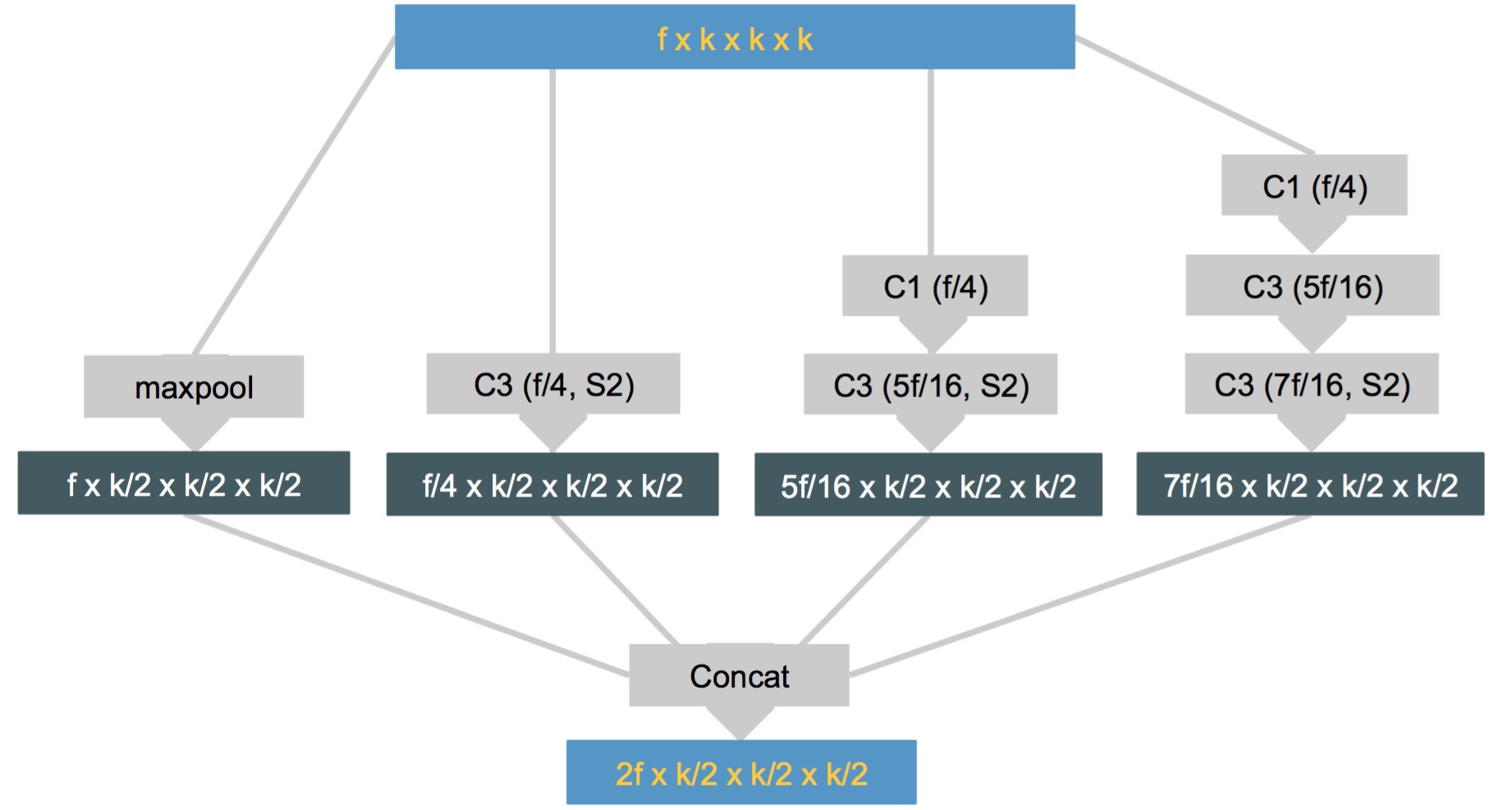
첫 번째 빌딩 블록은 공간 축소 블록 입니다. 입력 텐서의 공간 차원은 서로 다른 축소 접근법을 적용하여 절반이됩니다. 한 손에는 최대 풀링이, 다른 손에는 길쌈 된 길쌈 레이어가 있습니다.
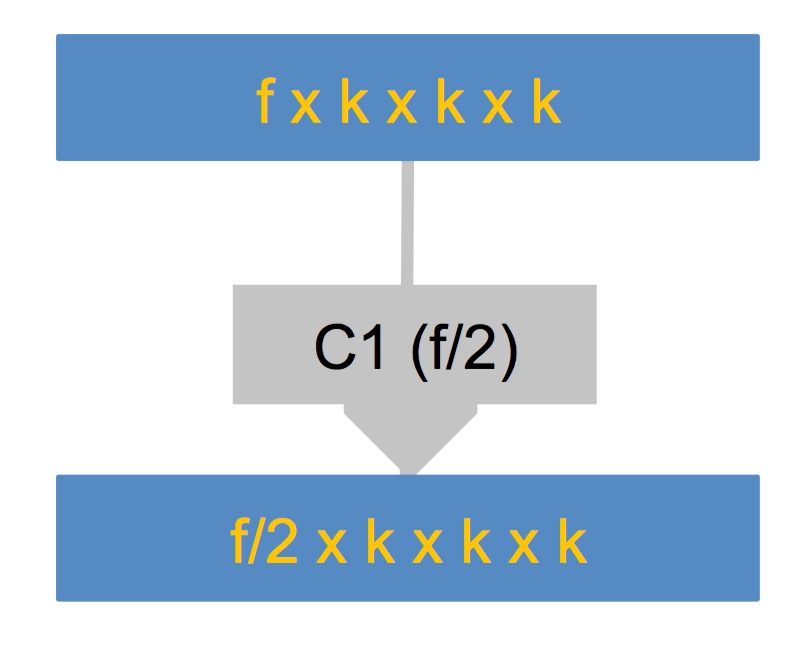
상기 특징 감소 블록 은 1x1x1 필터 커널을 갖는 길쌈 층 (convolutional layer)이 특징들의 수를 감소 시키는데 사용되는 단순한 블록이다. 필터 커널의 수는 입력 된 기능 맵의 수의 절반입니다.
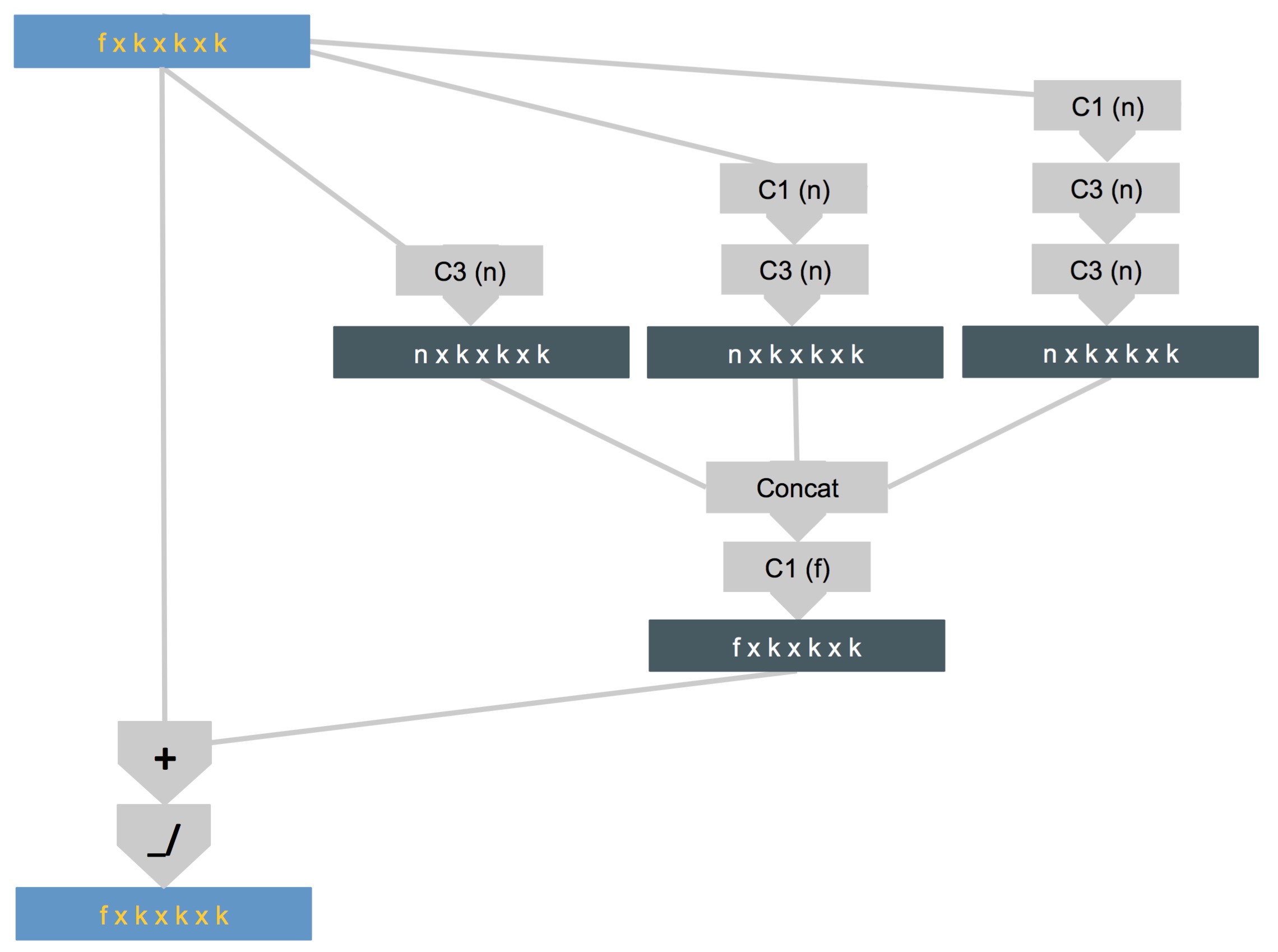
잔류 컨벌루션 블록 층의 수가 다른 컨벌루션 층 블록의 세 가지 스택을 각각 포함한다. 가장 얕은 스택은 1x1x1 필터를 가진 하나의 전환 레이어 만 있기 때문에 수용 필드를 넓히지 않습니다. 그러나 가장 깊은 스택은 수용 필드를 5x5x5로 넓 힙니다. 서로 다른 스택의 특성 맵은 블록의 입력 특성 맵의 수와 일치하도록 연결 및 축소됩니다. 축소 된 지형지 물 맵은 입력 맵에 추가됩니다. 이것은 네트워크가 더 많은 콘볼 루션 계층을 가질 필요가 없다고 판단 할 경우 트레이닝 중에 잔여 블록을 스킵 할 수있게 해준다. 마지막으로 ReLu 비선형 성은 결과 테너의 활성화에 적용됩니다.
우리는 이러한 빌딩 블록을 실험했으며 위양성 감소 작업에서 가장 뛰어난 성능을 보이기 위해 다음 아키텍처를 발견했습니다.
|
1
2
삼
4
5
6
7
8
9
10
11
12
13
14
15 명
16
17 세
18
|
def build_model(l_in): l = conv3d(l_in, 64) l = spatial_red_block(l) l = res_conv_block(l) l = spatial_red_block(l) l = res_conv_block(l) l = spatial_red_block(l) l = res_conv_block(l) l = feat_red(l) l = res_conv_block(l) l = feat_red(l) l = dense(drop(l), 128) l_out = DenseLayer(l, num_units=1, nonlinearity=sigmoid) return l_out |
원래의 시작과 중요한 차이점은 우리 네트워크의 시작 부분에 하나의 길쌈 레이어 만 있다는 것입니다. 원래의 리셋 v2 아키텍처에는 스템 블록이있어 입력 이미지의 크기를 줄였습니다.
결과
LUNA 데이터 세트의 검증 서브 세트는 총 238 개의 결절을 가진 118 명의 환자로 구성됩니다. 세그멘테이션 및 얼룩 검출 후 238 개의 결절 중 229 개가 발견되지만 약 17,000 개의 오진 (false positives)이 있습니다. 가양 성을 줄이기 위해 후보자는 위양성 감축 네트워크에 의해 주어진 예측에 따라 순위가 매겨집니다.
| 상단 | 진정한 긍정 | 거짓 긍정 |
|---|---|---|
| 10 | 221 | 959 |
| 4 | 187 | 285 |
| 2 | 147 | 89 |
| 1 | 99 | 19 |
악성 종양 예측
경쟁 2 주 만에 LUNA 데이터 세트의 결절에 악성 표지가 있다는 것을 발견했습니다. 이 레이블은 LUNA가 기반으로하는 LIDC-IDRI 데이터 세트의 일부입니다. LIDC-IDRI의 경우 4 명의 방사선 전문의가 서로 다른 속성에 대해 1에서 5까지의 척도로 점수를 매겼다. Kaggle 토론 게시판에 대한 토론은 주로 LUNA 데이터 세트에 초점을 맞추었지만 LB의 최상위 점수에 근접 할 수있는 개별 결절 / 패치의 악성 예측 모델을 훈련했을 때만이었습니다.
|
1
2
삼
4
5
6
7
8
9
10
11
12
13
14
15 명
|
def build_model(l_in): l = conv3d(l_in, 64) l = spatial_red_block(l) l = res_conv_block(l) l = spatial_red_block(l) l = res_conv_block(l) l = spatial_red_block(l) l = spatial_red_block(l) l = dense(drop(l), 512) l_out = DenseLayer(l, num_units=1, nonlinearity=sigmoid) return l_out |
우리가 사용한 네트워크는 FPR 네트워크 아키텍처와 매우 유사합니다. 간단히 말하면, 그것은 더 많은 공간 감소 블록을 가지며, 마지막에서 두 번째 계층에 더 밀집된 단위를 가지며 기능 감소 블록을 갖지 않습니다.
우리는 악성 라벨을 0에서 1 사이의 값으로 표현하여 확률 라벨을 만들었습니다. 우리는 LUNA 데이터 세트에 악성 표지가없는 후보 결절과 동일한 양의 표본을 추출하여 훈련 세트를 만들었습니다.
객관적인 함수로서, 우리는 2 진 교차 엔트로피 목적 함수보다 잘 작동하는 것으로 보이는 평균 제곱 오류 (MSE) 손실을 사용했습니다.
폐암 예측
우리가 위양성 감소 네트워크로 후보 결절을 분류하고 악성 예측 네트워크를 훈련 한 후에 우리는 마침내 Kaggle 데이터 세트에서 폐암 예측을위한 네트워크를 훈련 할 수있었습니다. 우리의 전략은 동일한 서브 네트워크를 통해 n 개의 상위 후보 후보 결절 집합을 전송하고 최종 집계 계층에서 개별 점수 / 예측 / 활성화를 결합하는 것이 었습니다.
학습 이전
다양한 아키텍처를 처음부터 다시 연습 한 후에 좋은 기능을 추론 할 수있는 더 나은 방법이 필요하다는 것을 깨달았습니다. 우리가 전체 CT 스캔을 관심있는 여러 영역으로 축소했지만 환자 수는 여전히 낮으므로 악성 결절의 수가 여전히 낮습니다. 따라서 사전 훈련 된 가중치로 네트워크를 초기화하는 데 주력했습니다.
전송 학습 아이디어는 대부분의 전송 학습 방법이 ImageNet 데이터 세트에서 학습 한 네트워크를 자체 네트워크의 길쌈 레이어로 사용하는 RGB 이미지가있는 이미지 분류 작업에서 널리 사용됩니다. 그러므로 좋은 특징은 큰 데이터 집합에서 학습되고 다른 신경망 / 다른 분류 작업의 일부로 재사용 (전송)됩니다. 그러나 CT 스캔의 경우 우리는 그러한 사전 훈련 된 네트워크에 접근 할 수 없었으므로 우리는 스스로 훈련해야했습니다.
처음에는 이미 개선 된 fpr 네트워크를 사용했습니다. 결과적으로 LUNA 데이터 세트의 주석 일부이기 때문에 결절 크기를 예측하기 위해 네트워크를 교육했습니다. 두 경우 모두, 우리의 주요 전략은 길쌈 레이어를 재사용하고 밀도가 높은 레이어를 무작위로 초기화하는 것이 었습니다.
마지막 주에는 전체 악성 종양 네트워크를 사용하여 시작하여 집계 레이어를 추가했습니다. 그러나 우리는 어쨌든 모든 레이어를 재교육했습니다. 어떻게 든 논리적인데, 이것이 최고의 해결책이었습니다.
결절 예측 집계
우리는 결절의 악성 예측을 결합하기 위해 여러 가지 접근법을 시도했습니다. 가장 성공적인 두 가지 집계 전략을 강조합니다.
- P_patient_cancer = 1 – Π P_nodule_benign :이 집계의 배경은 모든 결절이 양성이면 암 발병 가능성이 1입니다. 한 개의 결절이 악성으로 분류되면 P_patient_cancer가 1이됩니다.
이 접근법의 문제점은 악성 예측 네트워크가 결절 중 하나가 악의적 인 것으로 확신 할 때 잘 작동하지 않는다는 것입니다. 네트워크가 결절 중 하나의 네트워크가 악성이라고 정확하게 예측하면 학습이 중단됩니다. - Log Mean Exponent :이 집계 전략의 배경은 암 확률이 가장 악성 / 최소 양성 결절에 의해 결정된다는 것입니다. LME 집계는 max 연산자의 소프트 버전으로 작동합니다. 이름에서 알 수 있듯이 지수 적으로 개별 결절 예측의 예측을 불어 넣어 가장 큰 확률에 초점을 맞 춥니 다. 단순한 max 함수와 비교할 때이 함수는 다른 예측의 네트워크를 통해 역 전파도 허용합니다.
앙상블
우리의 앙상블은 30 개의 마지막 무대 모델의 예측을 병합합니다. Kaggle은 두 가지 제출을 허용했기 때문에 두 가지 앙상블 방법을 사용했습니다.
- 방어 적 앙상블 : 내부 유효성 검증 세트에서 최적화 된 가중치를 사용하여 예측을 평균합니다. 이 과정에서 우리가 보았던 되풀이 주제는 앙상블에 사용 된 모델 수의 대폭 감소였습니다. 이는 모델 간의 유사성이 높기 때문에 발생합니다. 최종 제출을 위해 단 하나의 모델 만 선택 되었음이 밝혀졌습니다.
- 적극적인 앙상블 : 교차 검증은 균일하게 혼합 될 높은 점수의 모델을 선택하는 데 사용됩니다. 이 앙상블에 사용 된 모델은 모든 데이터에 대해 교육을 받았으므로 이름이 ‘공격적인 앙상블’입니다. 우리는 이러한 ‘좋은’모델을 균일하게 혼합하여 체중 최적화 중 높은 가지 치기 요인 때문에 매우 적은 모델로 앙상블을 완성 할 위험을 피합니다. 또한 과밀 모델의 영향을 줄여줍니다.앙상블과 강력하게 일치하지 않는 모델을 제거하여 테스트 환자 당 앙상블을 재 최적화하는 것은 최적화 과정에서 많은 모델이 정리 (pruned)되기 때문에 그다지 효과적이지 않습니다. 최종 앙상블 가중치를 선택하는 또 다른 방법은 CV 동안 선택된 가중치를 평균하는 것이 었습니다. 이것은 우리의 성과를 향상시키지 못했습니다. 우리는 트리 모델을 사용하여 예측을 쌓기도했지만 메타 기능이 없기 때문에 경쟁적으로 수행하지 못하고 앙상블의 안정성을 감소 시켰습니다.
최종 생각
도전의 큰 부분은 전체 시스템을 구축하는 것이 었습니다. 그것은 많은 단계로 이루어져 있으며 우리는 그것의 모든 부분을 완전히 미세 조정할 시간이 없었습니다. 따라서 개선의 여지는 여전히 많습니다. 도전 과제와 고귀한 목적을 위해 경쟁 조직 위원 들께 감사드립니다.
딥 브레스 팀
Andreas Verleysen @resivium
Elias Vansteenkiste @SaileNav
프레데릭 고딘 @frederic_godin
Ira Korshunova @iskorna
Jonas Degrave @ 317070
리오넬 피구 @lpigou
Matthias Freiberger @mfreib







+ There are no comments
Add yours