







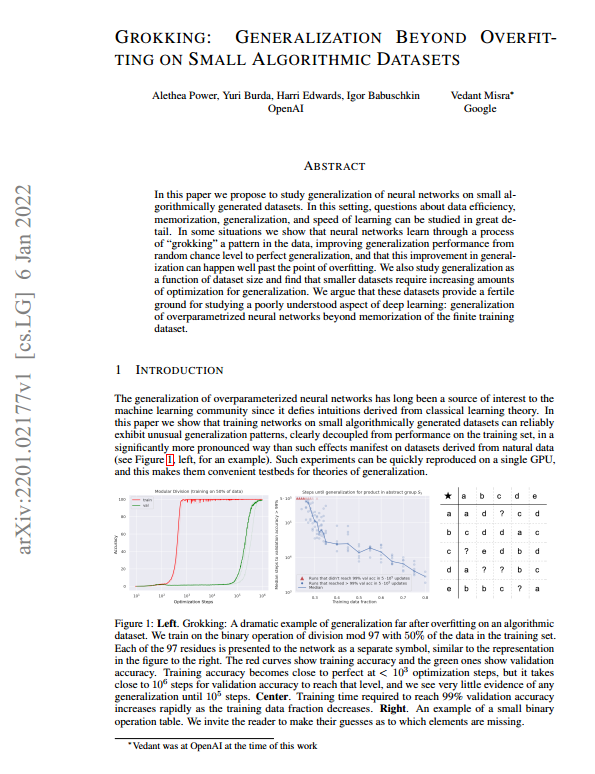
요약: 이 논문은 작은 알고리즘적으로 생성된 데이터셋에서 신경망의 일반화 능력을 연구하는 것을 제안합니다. 이러한 설정에서는 데이터 효율성, 기억, 일반화, 학습 속도에 대한 질문들을 자세히 연구할 수 있습니다. 일부 상황에서 신경망은 데이터의 패턴을 “이해”하는 과정을 통해 무작위 수준에서 완전한 일반화로 성능을 향상시킬 수 있으며, 과적합이 발생한 후에도 이러한 일반화 개선이 일어날 수 있습니다. 또한 데이터셋 크기에 따른 일반화를 연구하여 작은 데이터셋에서는 일반화를 위해 점점 더 많은 최적화가 필요하다는 것을 발견했습니다. 이 작은 알고리즘 데이터셋은 과대적합된 신경망의 일반화라는 잘 알려지지 않은 딥러닝 측면을 연구하기에 적합한 토대를 제공합니다.







+ There are no comments
Add yours