








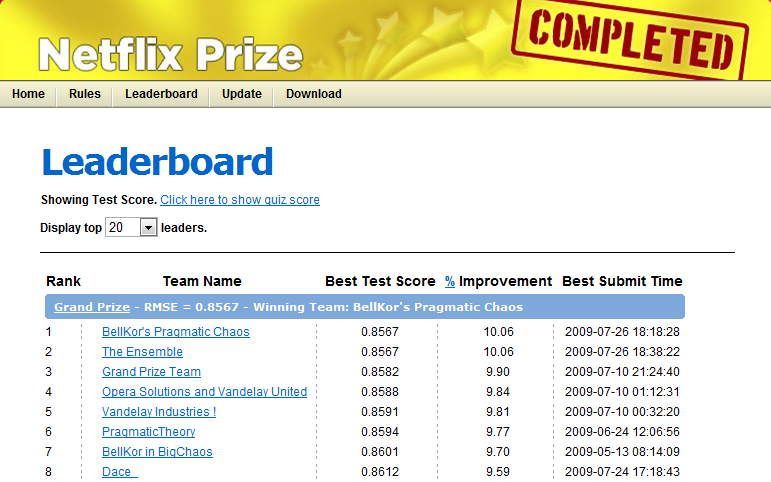
넷플릭스 사례의 분석
1. 기존보다정확도가 1위 10%향상, 2위 8.4%향상 되는 알고리즘을 얻은 후
넷플릭스는 구현에 드는 노력비용과 실제 얻을 수 있는 이익을 비교하여
2위의 알고리즘을 선택 적용하였음
2. 실제 현실세계에 적용을 위한 부분
경진대회 데이터세트에서의 평가 수는 1억개 였지만 실제 생산 시스템에는 50억개 이상
경진대회 데이터세트는 정적이지만 생산 시스템에서 평가의 수는 지속적으로 증가(하루에 400만개)
ㆍ “사람들이 시청하는 영화의 75%는 추천된 영화임.”
ㆍ “회원 경험을 지속적으로 최적화함으로써 회원 만족도가 크게 향상됨.”
3. Netflix가 가장 중요하게 발견한 사실 : 사용자 경험, 사용자 만족도 및 사용자 유지임
http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.html
(2006년 Netflix는 유명한 머신 러닝 및 데이 터 마이닝 경진대회인 “Netflix Prize”를 발표하 고 2009년에는 $100만의 상금을 내걸었습니다. 대중과 언론의 관심 속에 결국 어떤 솔루션이 우승했을까요? 실제 프로덕션에 채택되었을까 요? 그렇지 않다면, 왜 그랬을까요?)
https://kr.mathworks.com/campaigns/products/ppc/google/scalable-machine-learning-system.html?s_eid=ppc_28434964690&q= (관련 한글보고서 다운로드 하기)
89596_93026v00_KR_Netflix_Whitepaper







+ There are no comments
Add yours