








https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
2018 년 11 월 2 일 금요일Jacob Devlin과 Ming-Wei Chang, Google AI 언어 연구 과학자 자연 언어 처리 (NLP)
에서 가장 큰 과제 중 하나 는 교육 데이터가 부족하다는 것입니다. NLP는 많은 별개의 작업이 포함 된 다양한 분야이므로 대부분의 작업 별 데이터 세트에는 몇 천 개 또는 수십만 개의 인간 레이블이 지정된 교육 사례 만 포함됩니다. 그러나 현대의 심층 학습 기반 NLP 모델은 수백만 또는 수십억 개의 주석이 달린 교육 사례를 교육 할 때 훨씬 더 많은 양의 데이터로 인한 이점을 확인합니다 . 연구원은 데이터의 이러한 격차를 줄이기 위해 웹에서 주석이 달린 엄청난 양의 텍스트를 사용하여 범용 언어 표현 모델을 교육하기위한 다양한 기술을 개발했습니다 ( 사전 교육이라고 함).). 사전 훈련 된 모델은 질문 응답 및 정서 분석 과 같은 소규모 데이터 NLP 작업에서 미세 조정할 수 있으므로 이러한 데이터 세트를 처음부터 교육하는 것과 비교할 때 상당한 정확도 향상을 얻을 수 있습니다. 이번 주, 우리는 오픈 소스 화 라는 NLP 사전 훈련을위한 새로운 기술 B idirectional E를 ncoder R의 에서 epresentations T의 ransformers , 또는 BERT . 이 릴리스를 통해 전 세계 누구나 단일 클라우드 TPU에서 약 30 분 만에 자신의 최첨단 질문 응답 시스템 (또는 다양한 다른 모델)을 교육 할 수 있습니다.
또는 단일 GPU를 사용하여 몇 시간 내에 이 릴리스에는 TensorFlow 와 여러 가지 사전 훈련 된 언어 표현 모델 위에 구축 된 소스 코드가 포함되어 있습니다. 관련 논문 에서 우리는 매우 경쟁력있는 스탠포드 질문 응답 데이터 세트 (SQuAD v1.1)를 포함하여 11 가지의 NLP 작업에 대한 최첨단 결과를 보여줍니다 .
BERT가 다른 점은 무엇입니까?
BERT는 Semi-supervised Sequence Learning , Generative Pre-Training , ELMo 및 ULMFit을 포함한 상황 별 표현 사전 교육에 대한 최근 작업을 기반으로합니다 . 그러나 이전 모델과 달리 BERT는 최초의 양방향 지향성 제품으로 ,(이 경우, Wikipedia ) 만을 사용하여 사전 훈련 된 자막없는 언어 표현 입니다.
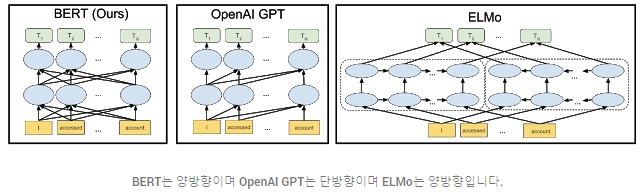
왜이 문제가 중요합니까? 사전 교육 된 표현은 문맥 자유형 또는 문맥 형일 수 있으며, 문맥 표현은 단방향 또는 양방향 일 수 있습니다. word2vec 또는 GloVe 와 같은 문맥없는 모델 은 어휘의 각 단어에 대한 단일 단어 임베딩 표현을 생성합니다 . 예를 들어, ” bank ” 라는 단어 는 ” bank account “와 “강의 은행. “대신 문맥 모델은 문장의 다른 단어를 기반으로하는 각 단어의 표현을 생성합니다. 예를 들어 ” 은행 계좌에 액세스했습니다. “문장 에서 단방향 문맥 모델은 ” 계정 “이 아닌 ” 액세스 한 “을 기반으로 ” 은행 “을 나타냅니다 . 그러나 BERT는 이전 및 다음 컨텍스트를 모두 사용하여 ” 은행 “을 나타냅니다 – 깊은 신경망의 맨 아래부터 시작하여 깊은 양방향으로 만들기 때문에 ” 계정에 액세스했습니다 . “
BERT의 신경 네트워크 아키텍처를 이전의 최첨단 상황 별 사전 교육 방법과 비교하여 시각화 한 것은 다음과 같습니다. 화살표는 한 레이어에서 다음 레이어로의 정보 흐름을 나타냅니다. 상단의 녹색 상자는 각 입력 단어의 최종 상황 별 표현을 나타냅니다.
| BERT는 양방향이며 OpenAI GPT는 단방향이며 ELMo는 양방향입니다. |
양방향성 의 강점 양방향성이 너무 강력하다면, 왜 전에는하지 않았습니까? 이유를 이해하려면 단방향 모델이 문장의 이전 단어에 조건이있는 각 단어를 예측하여 효율적으로 학습 된 것으로 간주하십시오. 그러나 이전 과 다음 단어에 각 단어를 간단히 조절하여 양방향 모델을 학습 할 수는 없습니다. 이렇게하면 다층 모델에서 간접적으로 “스스로를”예측할 수있는 단어가 허용되기 때문입니다.
이 문제를 해결하기 위해 입력의 일부 단어를 마스킹 한 다음 각 단어를 양방향으로 조건 설정하여 마스킹 된 단어를 예측하는 간단한 방법을 사용합니다. 예 :

이 아이디어는 매우 오랜 시간 동안 있었지만 , BERT는 심 신경 네트워크 사전 훈련에 성공적으로 처음 사용되었습니다.
두 문장을 감안할 때 : BERT는 텍스트 말뭉치로부터 생성 될 수있는 매우 간단한 작업에 사전 교육하여 문장 사이의 관계를 모델링 배운다 와 B 이고, B를 이용하여 실제 다음 뒤에 오는 문장 단지 코퍼스에서, 또는 임의의 문장? 예 :

클라우드 TPU로 교육
지금까지 설명한 모든 내용은 상당히 간단하게 보일 수 있습니다. 그래서 잘 작동하지 않는 부분은 무엇입니까? 클라우드 TPU . 클라우드 TPU를 사용하면 모델을 신속하게 실험, 디버그 및 조정할 수 있으므로 기존의 사전 교육 기술을 뛰어 넘는 데 중요한 역할을했습니다. 변압기 모델 아키텍처 2017 년 구글 연구진에 의해 개발은 또한 우리에게 우리가 BERT를 성공하는 데 필요한 기초를 주었다. Transformer는 우리의 오픈 소스 릴리스 와 tensor2tensor 라이브러리 에서 구현됩니다 .
BERT 결과
성능을 평가하기 위해 BERT와 다른 최첨단 NLP 시스템을 비교했습니다. BERT는 신경 네트워크 아키텍처에 대한 작업 별 변경 사항없이 거의 모든 결과를 달성했습니다. 일 반 V1.1 , BERT는 93.2 %의 F1 점수 (정확도의 척도), 91.2 %의 이전 91.6 %의 최신 점수 인간 수준 점수를 능가 달성 :
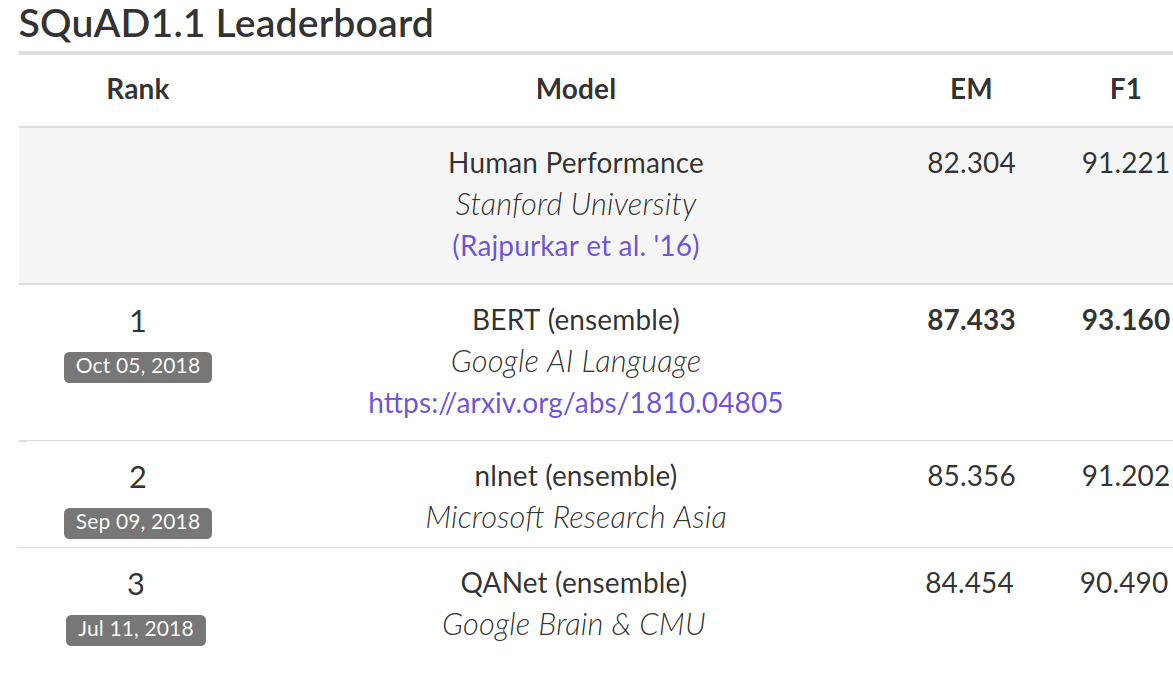
BERT는 또한 매우 까다로운 GLUE 벤치 마크 ( 9 가지 다양한 NLU (Natural Language Understanding) 작업 세트)에서 최첨단 기술력 을 7.6 % 향상시킵니다 . 이러한 작업에서 인간이 표기하는 교육 자료의 양은 2,500 개에서 400,000 개로 다양하며, BERT 는 그 모두에 대한 최첨단 정확도를 향상시킵니다 .

BERT 작동시키기
우리가 출시하는 모델은 몇 시간 이내에 다양한 NLP 작업을 미세 조정할 수 있습니다. 오픈 소스 릴리스에는 사전 교육을 실행하는 코드도 포함되어 있습니다. BERT를 사용하는 대다수의 NLP 연구원이 자신의 모델을 처음부터 미리 사전 설정할 필요는 없다고 생각합니다. 오늘 발표하는 BERT 모델은 영어 전용이지만, 가까운 미래에 다양한 언어로 사전 교육을받은 모델을 출시하기를 바랍니다.
오픈 소스 TensorFlow 구현 및 사전 교육 된 BERT 모델에 대한 지침은 http://goo.gl/language/bert에서 찾을 수 있습니다 . 또는 노트북 ” BERT FineTuning with Cloud TPUs ” 를 사용하여 Colab 을 통해 BERT를 사용할 수도 있습니다 .
자세한 내용 은 ” BERT : 언어 이해를위한 양방향 트랜스포머 사전 교육 “을 참조하십시오.
https://medium.com/ai-networkkr/최첨단-인공지최첨단-인공지능-솔루션들-1-구글-bert-인간보다-언어를-더-잘-이해하는-ai-모델-9704ebc016c4
BERT개발팀은 논문에 제시된 실험결과들을 얻기 위해서 다음과 같은 규모의 머신리소스를 사용했고 pre-training을 마치기 까지 4일 정도 소요되었다고 밝히고 있습니다.
- BERT-Base: 4 Cloud TPUs (16 TPU chips total)
- BERT-Large: 16 Cloud TPUs (64 TPU chips total)
이 리소스는 엄청난 양인데요, 개발자들은 만약 8개의 TESLA P100을 사용했다면 1년 넘게 걸렸을 수도 있다고 얘기하고 있습니다.
앞에서 언급했듯이 BERT 개발자들이 보여준 기본철학은
- 범용 솔루션을
- 스케일러블 한 형태로 구현해서
- 많은 머신리소스로 훈련해서 성능을 높인다
입니다.
BERT개발팀이 이미 소스코드와 학습된 모델을 공개했기 때문에 (참조링크) 이제 원한다면 누구나 BERT를 사용할 수 있습니다. 하지만 누구나 새로운 모델을 학습시킬 수 있다는 의미는 아닙니다.









+ There are no comments
Add yours