








[Coursera] Machine Learning Foundations A Case Study Approach – University of Washington
WEEK1
준비작업 : Datodml Graphlab 라이브러리, iPython Notebook 툴 이용, MatPlotLib 이용 등 사전에 익혀야 할 부분이 좀 있음, 그리고 당연히 파이썬은 조금이라도 알아야 함 ^^
install-graphlab-create-command-line 방법
Jupyter 실행관련
아나콘다 + Command 창에서 “activate dato-env” 이후 필요한 라이브러리 설치 및 “ipython notebook” 명령으로 jupyter 환경 실행(이게 이클립스 기반보다 강력한 부분이 있음)
WEEK2 (2016.4.10)
선형회귀에 대한 이론과 실습을 수행
퀴즈내용중 2번째는 약간 검색 또는 고민해야 할 부분이 있음
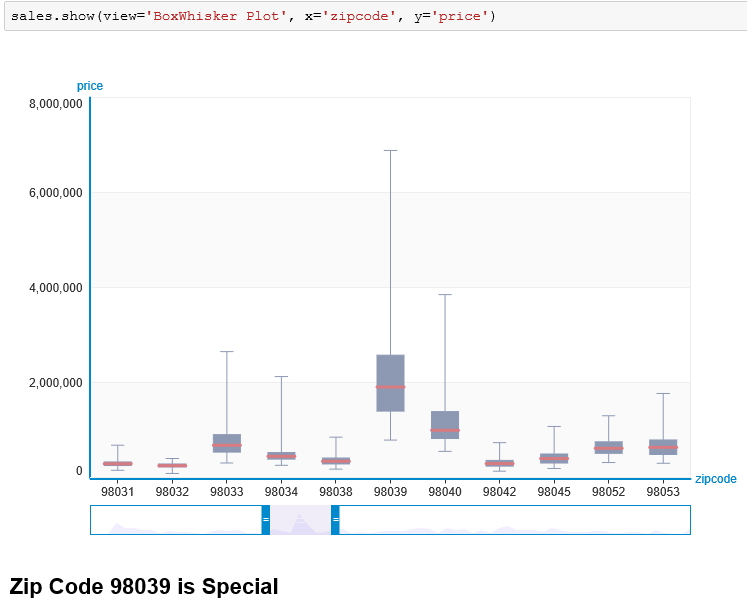
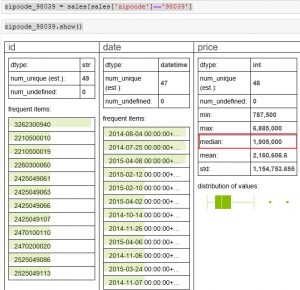
2-1 중요 힌트 : zipcode_98039 = sales[sales[‘zipcode’]==’98039′]
Week2-Quiz-2-2-1A
Week2-Quiz-2-2-1
2-2 중요힌트 : sales[sales[‘sqft_living’].apply(lambda x: 1 if int(x)>=2000 and int(x)<=4000 else 0)]
Week2-Quiz-2-2-2B
2-3 중요힌트 : several_features = [‘bedrooms’, ‘bathrooms’, ‘sqft_living’, ‘sqft_lot’,’floors’, ‘zipcode’,
‘waterfront’, ‘view’, ‘condition’, ‘grade’, ‘sqft_above’, ‘sqft_basement’,
‘yr_built’, ‘yr_renovated’, ‘lat’, ‘long’, ‘sqft_living15’, ‘sqft_lot15′]
several_features_model = graphlab.linear_regression.create(train_data, target=’price’, features=several_features)
several_features_model.evaluate(test_data)
Week2-Quiz-2-2-3A
Week 4 Similarity of Document
TF-IDF : Term frequency – inverse document frequency
Week4-tf_idf1
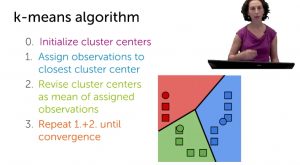
Week4-k-means algorithm
K-Means Algorithm은 매우 훌륭하게 설명하고 있음 (이해하기 매우 쉬움)
WEEK5 Jaccard Similarity











+ There are no comments
Add yours