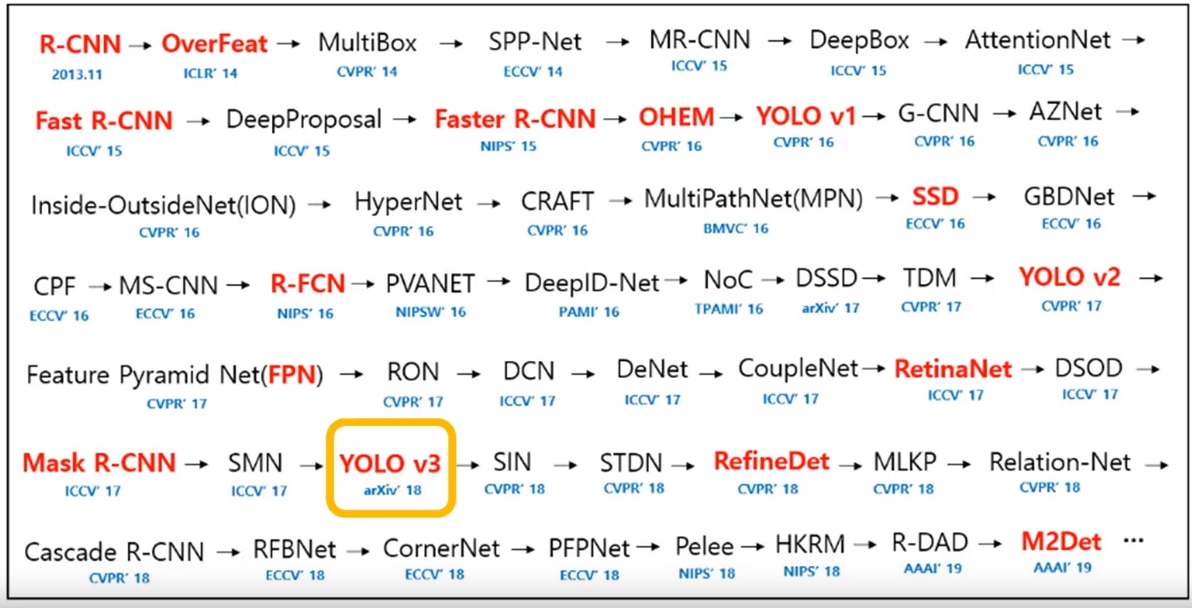

The Era of AI 게시자료_20241105-AI-시대Download https://www.youtube.com/watch?v=ISWInEO1puY [more ...]
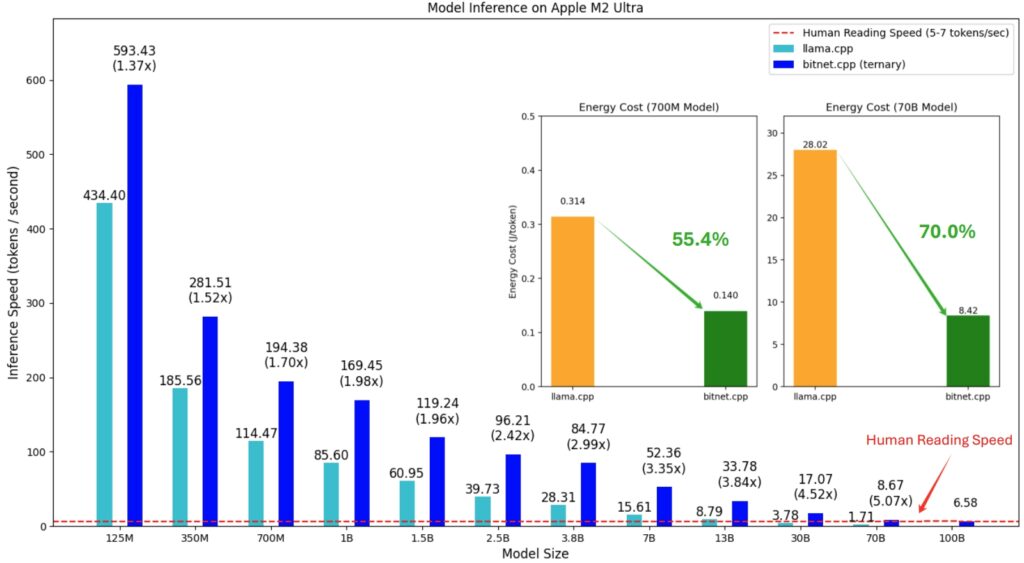
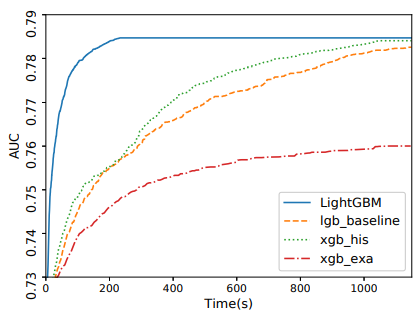
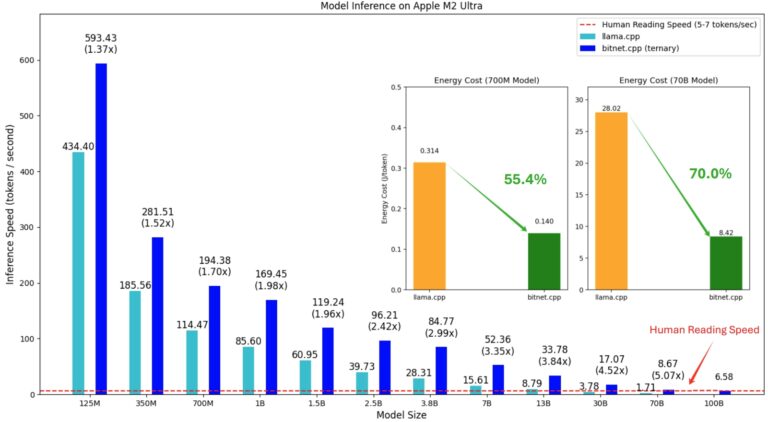
https://github.com/microsoft/BitNet m2_performanceDownload [more ...]
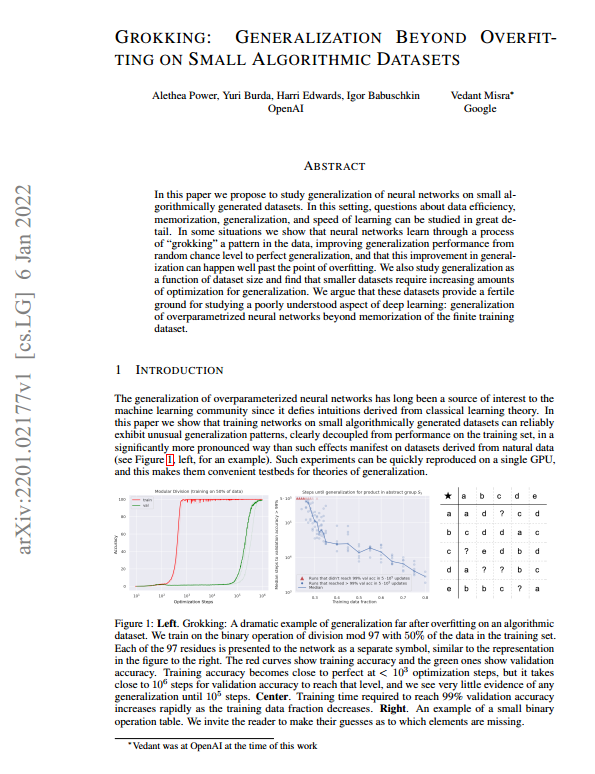
2201.02177-Grokking_kor_google_transDownload 요약: 이 논문은 작은 알고리즘적으로 생성된 데이터셋에서 신경망의 일반화 능력을 연구하는 것을 제안합니다. 이러한 설정에서는 데이터 효율성, 기억, 일반화, 학습 속도에 대한 질문들을 자세히 연구할 수 있습니다. 일부 상황에서 신경망은 데이터의 패턴을 "이해"하는 과정을 통해 무작위 수준에서 완전한 일반화로 성능을 향상시킬 수 있으며, 과적합이 발생한 후에도 이러한 일반화 개선이 [more ...]

인공 지능 시스템 규제 : 위험,과제, 역량 및 전략 SSRN-id2609777-1Download SSRN-id2609777Download [more ...]
The Era of AI 게시자료_20241105-AI-시대Download https://www.youtube.com/watch?v=ISWInEO1puY
https://github.com/microsoft/BitNet m2_performanceDownload
2201.02177-Grokking_kor_google_transDownload 요약: 이 논문은 작은 알고리즘적으로 생성된 데이터셋에서 신경망의 일반화 능력을 연구하는 것을 제안합니다. 이러한 설정에서는 데이터 효율성, 기억, 일반화, 학습 속도에 대한 질문들을 자세히 연구할 수 있습니다. 일부 상황에서 신경망은 데이터의 패턴을 "이해"하는 과정을 통해 무작위 수준에서 완전한 일반화로 성능을 향상시킬 수 있으며, 과적합이 발생한 후에도 이러한 일반화 개선이...

인공 지능 시스템 규제 : 위험,과제, 역량 및 전략 SSRN-id2609777-1Download SSRN-id2609777Download

Artificial Intelligence and Privacy (인공지능과 프라이버시) Artificial-Intelligence-and-Privacy-202401SSRN-id4713111_구글번역판_편집Download Artificial-Intelligence-and-Privacy-202401SSRN-id4713111Download 요약 이 논문은 인공지능(AI)과 개인정보 보호의 교차점에 대한 근본적인 이해를 확립하고, AI가 개인정보 보호에 제기하는 현재 문제를 간략하게 설명하고 이 분야에서 법의 발전을 위한 잠재적인 방향을 제시하는 것을 목표로 합니다. 지금까지 AI와 개인 정보 보호가 어떻게 상호 연관되는지에 대한 전반적인 환경을 탐구한...
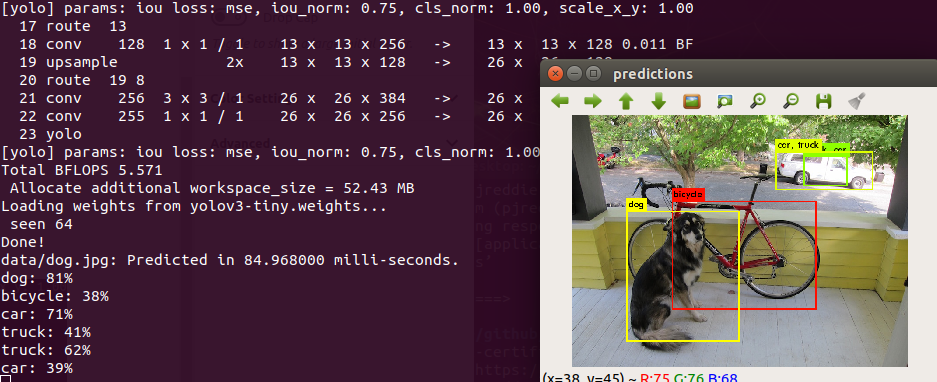
https://github.com/opendatacam/opendatacam/blob/master/documentation/USE_WITHOUT_DOCKER.md— memory issue https://github.com/opendatacam/opendatacam/issues/95 Jetpack 4.2.1 Default opencv 3.3.1 from jetpack Darknet with branch https://github.com/opendatacam/darknet/tree/opendatacam test case (20200124) – latest version testing… $ jetson_release NVIDIA Jetson [more…]
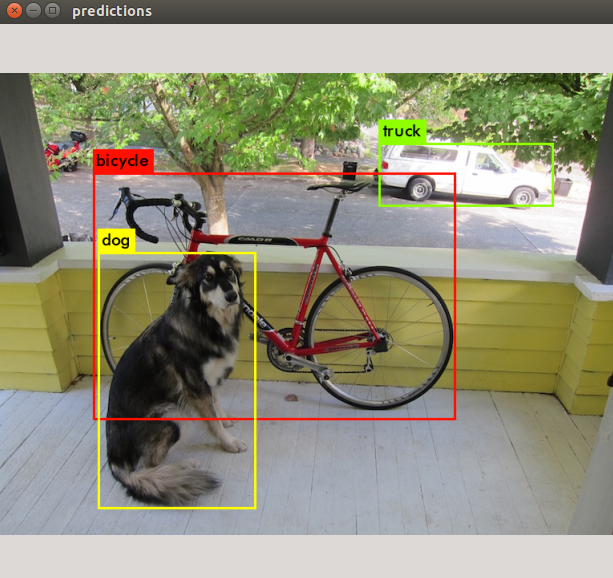
1. Fan control #For Preventing OverHeat (오버히트 방지를 위해 팬 장착) git clone https://github.com/Pyrestone/jetson-fan-ctlcd jetson-fan-ctl/sudo gedit /etc/automagic-fan/config.json 2. Camera Test method1 : gst-launch-1.0 nvarguscamerasrc ! [more…]
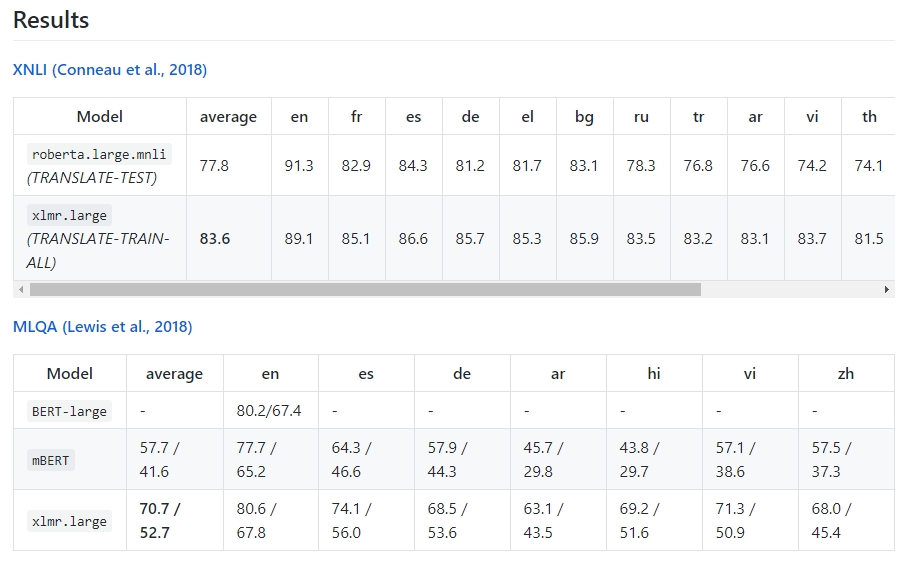
https://github.com/pytorch/fairseq XLM-R (XLM-RoBERTa) is a generic cross lingual sentence encoder that obtains state-of-the-art results on many cross-lingual understanding (XLU) benchmarks. It is trained on 2.5T [more…]
The International Mathematical Olympiad (IMO) https://imo-grand-challenge.github.io/?fbclid=IwAR1wNVWh9q72XZx12vFlj8Cg-MKC9D9apdc6duNKpSLsdmBVr6mSF-hqmTs fbclid=IwAR1wNVWh9q72XZx12vFlj8Cg-MKC9D9apdc6duNKpSLsdmBVr6mSF-hqmTs

berkeley-stat-157 https://courses.d2l.ai/berkeley-stat-157/syllabus.html?fbclid=IwAR1b79VuMqGaM4L0ADkl2lPFuz1gzpwIUnZe4tm5VccEaWD75mx-jArVUR0 코드, 수학, 토론이 함께하는대화형 딥러닝 학습서 https://ko.d2l.ai/?fbclid=IwAR1ginkGAVp7omPLDdiqez6fTbQs6XCIz4cN46YBf6ZtvntfGREb3XFjI0c